Деанонимизация программиста возможна не только через исходный код, но и через скомпилированный бинарный файл
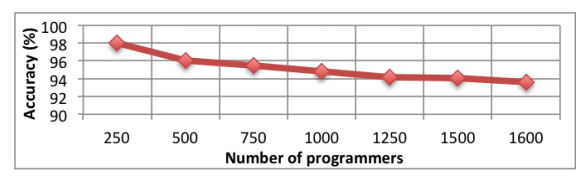
Не секрет, что многие разработчики программного обеспечения с открытым исходным кодом и не только, по разным причинам желают сохранить свою анонимность. Совсем недавно группа исследователей опубликовала работу, в которой описываются методы деанонимизации программиста по его стилю кодирования через анализ исходных кодов. Авторы утверждают, что им удалось достигнуть средней точности идентификации в 94%.
С помощью построения абстрактных синтаксических деревьев на основе разбора исходного текста, им удалось выделить устойчивые отличительные признаки при написании кода, которые трудно скрыть даже целенаправленно. Используя машинное обучение и набор эвристик, удалось добиться впечатляющей точности определения авторства среди выборки из 1600 программистов Google Code Jam.
В своей новой работе, исследователи продемонстрировали, что деанонимизация возможна и через анализ уже скомпилированных бинарных файлов в отсутствии исходных кодов (видео презентации доклада). В этот раз для исследования использовались исходные коды 600 участников Google Code Jam, которые были скомпилированы в исполняемые файлы, а потом подвергались разбору. Благодаря тому, что задания на соревнованиях были одинаковы для всех, разница файлов заключалась в значительной степени именно в стиле программирования, а не в алгоритме. Изначально, при сборке бинарных файлов отключались оптимизации копилятора и не применялась обфускация исходных кодов. Но, как утверждают авторы работы, некоторые отличительные признаки сохраняются и при применении этих способов сокрытия авторства, снижая точность деанонимизации до 65%.
Читать дальше →
С помощью построения абстрактных синтаксических деревьев на основе разбора исходного текста, им удалось выделить устойчивые отличительные признаки при написании кода, которые трудно скрыть даже целенаправленно. Используя машинное обучение и набор эвристик, удалось добиться впечатляющей точности определения авторства среди выборки из 1600 программистов Google Code Jam.
В своей новой работе, исследователи продемонстрировали, что деанонимизация возможна и через анализ уже скомпилированных бинарных файлов в отсутствии исходных кодов (видео презентации доклада). В этот раз для исследования использовались исходные коды 600 участников Google Code Jam, которые были скомпилированы в исполняемые файлы, а потом подвергались разбору. Благодаря тому, что задания на соревнованиях были одинаковы для всех, разница файлов заключалась в значительной степени именно в стиле программирования, а не в алгоритме. Изначально, при сборке бинарных файлов отключались оптимизации копилятора и не применялась обфускация исходных кодов. Но, как утверждают авторы работы, некоторые отличительные признаки сохраняются и при применении этих способов сокрытия авторства, снижая точность деанонимизации до 65%.
Читать дальше →
Источник: Хабрахабр



